
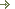
Отображение структуры реляционной СУБД в виде дерева при реализации пользовательского интерфейса
Использование древовидного отображения структуры реляционных СУБД при реализации пользовательского интерфейса дает ряд преимуществ, связанных с удобством навигации по элементам СУБД и администрированию. При этом способ построения такой структуры определяет время загрузки приложения и навигации по объектам в процессе работы. И если при реализации работы системы в режиме standalone выбор того или иного способа организации построения дерева не существенно сказывается на временных характеристиках, то при реализации распределенного приложения это сильно влияет на производительность всей системы в целом и является критичным. В этом случае, так же, по мимо выбора реализации способа построения древовидной структуры, на производительность системы влияет выбор стратегии кэширования и механизма транзакций.
Целью данной работы является анализ способов построение древовидной структуры при разработке распределенной системы "Учет электротехнического оборудования ОАО "РОСТОВЭНЕРГО" и выбора оптимального из них с использованием технологий Java 2 [1], СУБД HSQLDB [2], MS SQL Server и Hibernate[3] как средства отображения данных объектной модели на реляционную. Новизна работы заключается в том, что при реализации трехзвенной архитектуры распределенного приложения, слой, отвечающий за доступ к СУБД, реализован с помощью библиотеки Hibernate [4,5].
По способу загрузки элементов в древовидную структуру можно выделить статическое и динамическое построение дерева. Статическое построение дерева, как правило используется, когда заранее известна иерархическая структура, т.е. количество уровней. Отличительной особенностью такого построения является то, что в дальнейшей работе при попытке перейти на низший уровень не выполняется запросов к СУБД, т.е. дерево формируется сразу при загрузке программы и все дальнейшие манипуляции, связанные со вставкой или удалением нового объекта в дерево необходимо синхронизировать с СУБД. При динамическом построении, при загрузке формируется только самый высший уровень, а при попытке перейти к низшим уровням отслеживается соответствующее событие, например двойной «клик» на узле дерева, при этом формируется соответствующий запрос к СУБД, в результате которого осуществляется подгруздка необходимых данных в соответствующий узел.
Так же следует заметить, что при статической реализации возможны следующие варианты:
- алгоритмы построения дерева строго определены в коде;
- в коде отсутствует строгая реализация построения, а используется модуль, реализованный в виде интерфейса в котором описаны методы построения и заполнения узла дерева, а иерархия объектов дерева реализованная в виде XML файла конфигурации.
К недостаткам первого способа можно отнести невозможность оперативного внесения каких либо корректив при изменении структуры, а также наложения каких либо ограничений на выборку бизнес объектов, например запрос с параметром и необходимость перекомпиляции исходных кодов в случае если такие изменения необходимо выполнить, что в конечном итоге сказывается на общем времени внесения изменений. К преимуществам данного способа следует отнести относительно небольшое время построения дерева, так как оно выполняется по четко запрограммированным алгоритмам для каждого конкретного объекта, а также размер дистрибутива, так как используются стандартные библиотеки.
Второй способ статического построения является более гибким и связано это с тем, что все взаимосвязи объектов, а также ограничения, которые накладываются на выборку можно указать в тэгах XML документа, который будет проанализирован при загрузке дерева. Вместе с тем, у данного способа есть недостатки, которые прежде всего связаны с временем построения и загрузки приложения.

Рисунок 1. Класс для отображения экземпляра сущности в узле

Рисунок 2. Класс объекта "групипровки" (GroupNode)
При разработке алгоритмов построения дерева, был учтен характер сложных взаимосвязей объектов СУБД, распределенный характер приложения, и объемы хранимой информации.
На первом этапе были определены элементы, которые будут загружаться в узлы дерева. Так как главное назначение дерева отображать структуру связанных сущностей СУБД, то основной вопрос связан с тем в каком виде загружать информацию о сущности, так как если загружать всю информацию о бизнес сущности в узел, т.е. бизнес объект со всеми его атрибутами, то это может привести к неоправданному расходу ресурсов, которые связаны как с выделением памяти под структуру, так и с нагрузкой на СУБД. Поэтому был создан специальный объект для отображения сущности в дереве (NodeTreeObj), рисунок 1, который в хранит только идентификатор сущности, ее класс и название, а для отображения имени объекта в узле дерева, в его классе был переопределен метод toString(). В связи с тем, что бизнес объекты имеют сложные взаимосвязи, и стержневые сущности могут иметь множество характеристических, т.е. одни объект может “агрегировать” множество объектов разных классов, при чем в зависимости от ситуации детализация объекта может быть разной, было принято решение создать специальный объект группировки (GroupNode), рисунок 2, с помощью которого можно было бы решать поставленную задачу. Взаимосвязь между данными объектами в дереве следующая, объект группировки может содержать множество объектов NodeTreeObj. Объект NodeTreeObj может содержать в себе как объекты GroupNode так и объекты NodeTreeObj.
Логику построения дерева при загрузке программы можно описать следующим образом. В начале должен анализироваться xml документ, в результате чего в памяти создается коллекция объектов группировки в виде списка - ArrayList. Как видно из рис.2 класс объекта группировки GroupNode, является полиморфическим, т.е. в зависимости от значений тэгов xml документа может иметь две различные реализации. В данном случае анализируется тэг – признак "наличие запроса с параметром к СУБД". Если данный тэг не установлен, то формируется Hibernate – запрос на выборку всех экземпляров сущности, Листинг 1.
Листинг 1. Фрагмент кода, класса SAX - анализатора.
/**
* Метод обработки начала элемента
*/
public void startElement(String uri, String Sname,
String qname, Attributes attr)throws SAXException
{
// Обработка события на начало тэга
if(qname.equals("groupnode"))
{
try {
baseObject = Class.forName(attr.getValue("baseobject"));
parNameNode = attr.getValue("parnamenode");
parent = Class.forName(attr.getValue("parent"));
visible = new Boolean(attr.getValue("visible")).booleanValue();
enabled = new Boolean(attr.getValue("enabled")).booleanValue();
parameter = new Boolean(attr.getValue("parameter")).booleanValue();
nameNode = attr.getValue("namenode") ;
// Создаем экземпляр классаGroupNode...
//проверяем есть ли запрос с параметром
if(parameter)
{
nameField = attr.getValue("nameField");
typeField = attr.getValue("typeField");
valueField = attr.getValue("valueField");
groupNode = new GroupNode(baseObject,nameNode,parNameNode, parent,
visible,enabled,parameter,nameField,typeField,valueField);
}
else
groupNode = new GroupNode(baseObject,nameNode, parNameNode,
parent,visible,enabled,parameter);
listGroupNode.add(groupNode);
} catch (ClassNotFoundException ex)
{
ex.printStackTrace();
}
..........
..........
Листинг 2. Фрагмент конфигурационного xml - файла, для построения дерева
<config;>
<!-- Описание элементов и атрибутов:
Элемент:
groupnode – элемент объект - группировки
Атрибуты:
baseobject- основная бизнес сущность, объекты которой выбираются в
групповую ноду из СУБД
nameNod - наименование узла для отображения в дереве
parnamenode - имя родительского узла группировки
parent - имя родительского класса бизнес сущности
(Варианты значений:
1. имя имеющейса бизнесс сущности с точным указанием пакета, например
ru.rosten.glip.entities.OrgUnit
2. если узел корневой то класс "javax.swing.tree.TreeNode")
visible - Признак видимости групипровки
enabled - признак доступности
parameter - признак наличия параметров запроса при выборке бизнес сущности в
групповой узел (flase - нет параметров true – есть)
namefield - имя поля
type – тип поля (long или String)
value - значение параметра
-->
<!--Корневая нода для организаций -->
<groupnode; baseobject="ru.rosten.glip.entities.OrgUnit"
namenode="Сетевые компании"
parnamenode="Root"
parent="javax.swing.tree.TreeNode"
visible="true"
enabled="true"
parameter="true"
nameField="orgUnitLevel"
typeField="long"
valueField="1"
/>
<!--Нода для организаций второго уровня -->
<groupnode; baseobject="ru.rosten.glip.entities.OrgUnit"
namenode="ПЭС"
parnamenode="Сетевые компании"
parent="ru.rosten.glip.entities.OrgUnit"
visible="true"
enabled="true"
parameter="false"
nameField="orgUnitLevel"
typeField="long"
valueField="2"
/>
После того, как в памяти созданы все объекты группировки, начинается процесс формирования дерева и вывода его на экран. Далее уже все основные манипуляции осуществляются через коллекцию созданных объектов в памяти. В начале выбираются корневые объекты, от которых уже выполняются дальнейшие построения, Листинг 3.
Листинг 3. Фрагмент кода создания корневых элементов.
listGroupNode = treeHandler.getListGroupNode();
for (Object elem : listGroupNode)
{
// проверяем загруженный список на наличие корневых нод
if(javax.swing.tree.TreeNode.class.equals(((GroupNode) elem).getParentObj()))
{
root.add((GroupNode) elem);
// проверяем есть ли запросы с параметром
if(((GroupNode) elem).isParameter()){
// если есть проверяем какого типа параметр
if(((GroupNode) elem).getTypeField().equals("String"))
this.createNode((GroupNode) elem,queryDB.getParamColNto(
((GroupNode) elem).getBaseObject(),
((GroupNode) elem).getNameField(),
((GroupNode) elem).getValueField(),
((GroupNode) elem).getValueField()
));
if(((GroupNode) elem).getTypeField().equals("long"))
this.createNode((GroupNode) elem,queryDB.getParamColNto(
((GroupNode) elem).getBaseObject(),
((GroupNode) elem).getNameField(),
new Integer(((GroupNode) elem).getValueField()).intValue()
));
}
else
{
this.createNode((GroupNode) elem,queryDB.getColNto(
((GroupNode) elem).getBaseObject() ));
}
}
После чего начинается вызов группы методов, основное назначение которых, состоит в том, чтобы создать узел дерева, заполнить его объектами группировки, в каждый из которых занести объект отображения бизнес сущности. Данные методы выполняются один за другим последовательно, один метод вызывает другой, образуя таки образом логическое "кольцо", до тех пор, пока не будет полностью построено дерево, Листинг 4-7.
Листинг 4. Метод для создания узлов дерева на базе объекта NodeTreeObj
/**
* Метод для создания узлов дерева на базе объекта NodeTreeObj
* @param groupNode нода группировки
* @param listNode список нод
*/
public void createNode(DefaultMutableTreeNode groupNode,List listNode){
for (NodeTreeObj nto :listNode )
{
DefaultMutableTreeNode dtmT = new DefaultMutableTreeNode(nto);
groupNode.add(dtmT);
fillGroupNode((GroupNode) groupNode,dtmT);
}
}
Основное назначение данного метода заключается в создании узла дерева на базе экземпляра бизнес сущности и вызове метода для создания объекта группировки.
Листинг 5. Метод формирующий узел с объектом группировки
/**
* Метод формирующий узел с объектом группировки
* @param groupNode Групповая нода
* @param dmtn Нода с объектом NodeTreeObj в которую при определенных
* условиях должен вставиться узел группировки
*/
void fillGroupNode(GroupNode groupNode,DefaultMutableTreeNode dmtn)
{
NodeTreeObj ntoL = (NodeTreeObj) dmtn.getUserObject();
for (GroupNode tmpGroupNode : this.getListGroupNode()) {
if(tmpGroupNode.getParNameNode().equals(groupNode.toString()))
{
try{
// Определяем базовую бизнес сущность для узла группировки
if( tmpGroupNode.getParentObj() = = ntoL.getNameCls())
{
// Создание класса по шаблону
GroupNode realGroupNode =(GroupNode)tmpGroupNode.clone();
dmtn.add(realGroupNode);
fillNodeTree(realGroupNode, ntoL);
}
}catch(Exception ex){ex.printStackTrace();}
}
}
}
С помощью данного метода, определяется структура узла, содержащего объект бизнес сущности. Перебирается коллекция объектов группировки, и в случае совпадения базового класса коллекции с классом бизнес сущности, создается копия (клон) объекта группировки, после чего вызывается метод заполнения узла.
Листинг 6. Метод для заполнения узла содержащего объект NodeTreeObj
/**
* Метод для заполнения узла содержащего объект NodeTreeObj
* @param fGroupNode дочерний групповой объект
* @param nto Родительский объект
*/
public void fillNodeTree(GroupNode fGroupNode, NodeTreeObj nto){
try{
Method meId = fGroupNode.getBaseObject().getMethod("getId");
Method meName = fGroupNode.getBaseObject().getMethod("getName");
// Находим метод вызова дочерних объектов определенного класса
Method nesMethod = this.getNesMethod(nto.getNameCls(), fGroupNode.getBaseObject());
Object obj = queryDB.getObjTreeDB(nto);
Set list = (Set) nesMethod.invoke(obj);
if (list!=null){
List listNto = new ArrayList();
for ( Object elem : list)
{
// вызываем эти методы и заносим полученные данные в коллекцию
NodeTreeObj nto1 = new NodeTreeObj(
new Long(meId.invoke(elem).toString()).longValue(),
fGroupNode.getBaseObject(),
meName.invoke(elem).toString()
);
listNto.add(nto1);
}
this.createNode(fGroupNode,listNto);
}
}catch(Exception exp){ exp.printStackTrace();}
}
В данном методе используется механизм динамического отображения информации о классе, реализованный в библиотеке Reflection. Следует заменить, что еще на этапе проектирования, при реализации UML диаграмм, было принято, что каждая бизнес сущность должна содержать два обязательных атрибута, идентификатор (id) и имя (name), а также использовать параметризованные коллекции, при реализации отношения агрегации или

Рисунок 3. Фрагмент диаграммы классов
Листинг 7. Фрагмент кода бизнес объекта OrgUnit
// Описание и инициализация коллекции
private Set <OrgUnit;> orgUnits = new HashSet();
// Метод установки дочернего объекта
public void setOrgUnits(Set orgUnits) {
this.orgUnits = orgUnits;
}
//Метод получения дочернего объекта
public Set <OrgUnit;> getOrgUnits() {
return orgUnits;
}
Листинг 8. Фрагмент Hibernate - мэппинга бизнес сущности OrgUnit.
<!-- Коолекция дочерних организаций-->
<set; cascade="all"
inverse="true"
batch-size="9"
name="OrgUnits">
<key; column="ParentOrgUnit_id"/>
<one-to-many; class="ru.rosten.glip.entities.OrgUnit"/>
</set>
Это позволяет определять динамически тип возвращаемой коллекции, и вызывать соответствующий метод для ее получения, Листинг 9.
Листинг 9. Метод возвращающий объект класса Method (метод) для загрузки в узел дочерних объектов
/**
* Метод возвращающий объект класса Method (метод) для загрузки в узел дочерних объектов
* @param cls Класс объекта
* @return Искомый метод
* @param clsList Базовый тип объекта группировки, который указывает,
* какого типа должен быть возвращаемый объект искомым методом
*/
public Method getNesMethod(Class cls, Class clsList){
Method [] allMethods = cls.getMethods();
Method nesMethod = null;
for (int i = 0; i < allMethods.length; i++)
{
// проверка маской на наличие в имени метода строки «get»,
//а так же на то, что возвращаемый класс является параметризованным
if(allMethods[i].getName().indexOf("get")!=-1 &&
allMethods[i].getGenericReturnType() instanceof ParameterizedType )
{
Type[] l_list= ((ParameterizedType)allMethods[i].getGenericReturnType()).
getActualTypeArguments();
for(int j = 0; j < l_list.length; j ++)
{
if(l_list[j]== clsList)
{
nesMethod = allMethods[i];
break;
}
}
}
}
return nesMethod;
}
Однако, описанный выше подход не позволяет решить проблему загрузки бизнес объектов в дерево, когда не известна точно их иерархическая структура. Например, при привязке высоковольтных линий и отпаек к организации, заранее неизвестно ни количество уровней, ни количество отпаек от каждой линии. Поэтому в этом случае необходимо реализовать динамическую подгрузку. Для того, чтобы снизить нагрузку на СУБД, перед тем как выполнить запрос, анализируется, имеет ли узел, дочерние подузлы, и если подузлы есть то запрос к базе не выполняется, так как в текущем сеансе уже для данного узла была выполнена подгрузка.
Листинг 10. Мтоде динамической подгрузки элемента в дерево
/**
*Метод, который динамически подгружает по мере необходимости отпайки,
* так как структура их вложенности неизвестна.
*@param selPath узел над которым сделан двойной клик мышкой.
*/
public void LoadNode(DefaultMutableTreeNode selPath){
NodeTreeObj nto;
// Перебираем дочерние элементы узла
for (Enumeration enu = selPath.children(); enu.hasMoreElements();) {
Object tmpO = enu.nextElement();
DefaultMutableTreeNode tmpT = (DefaultMutableTreeNode)tmpO;
nto = (NodeTreeObj)tmpT.getUserObject();
if(tmpT.getChildCount()==0){
PowerLine tap=(PowerLine) queryDB.getObjTreeDB(nto);
Iterator tapIt = tap.getTapLines().iterator();
while (tapIt.hasNext()) {
tap = (TapLine) tapIt.next();
// Создаем новый объект для отображения бизнес сущности в дереве
nto = new NodeTreeObj(tap.getId(),tap.getClass(),tap.getName());
DefaultMutableTreeNode tmpTap = new DefaultMutableTreeNode(nto);
// вставляем его в родительский узел
tmpT.insert(tmpTap,tmpT.getChildCount());
}
}
}
}
Таким образом, использование комбинированного способа загрузки и построения дерева, при разработке распределенной системы позволяет снизить нагрузку на СУБД, минимизировать время загрузки клиентской части, гибко и оперативно изменять отображаемую структуру.
Список используемых источников
- www.sun.com – Сайт разработчика языка Java;
- http://hibernate.org – Сайт проекта Hibenate
- Hibernate in action. Bauer C., Gavin K. Manning Publications Co. 2005
- Hibernate Quickly. Patrick Peak, Nick Heudecker. Manning Publications Co. 2006



 Узнай о чем ты на самом деле сейчас думаешь
Узнай о чем ты на самом деле сейчас думаешь 

