
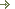
Кодовые точки Unicode и русские символы в исходных кодах и программах Java. JDK 1.6.
Достаточно много разработчиков программного обеспечения в действительности не имеют до конца четкого представления о наборах символов, кодировок, Unicode и сопутствующих материалах. Даже в настоящее время многими программами часто игнорируются встречающиеся преобразования символов, даже программами, которые, казалось бы, разработаны с помощью дружественных к Unicode Java технологиях. Зачастую беспечно используется для символов 8 битов, что делает невозможным разработку хороших многоязычных web-приложений. Данная статья является объединением рядов статей по вопросам кодировки Unicode, однако основополагающей стала переработанная статья Джоэла Сполски The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (08.10.2003).История создания различных видов кодировок
Весь тот материал, который говорит о том, что "простой текст = ASCII = символы из 8 бит", является не корректным. Единственными символами, которые могли отображаться корректно при любых обстоятельствах, это были английские буквы без диакритических знаков с кодами от 32 до 127. Для этих символов существует код, названный ASCII, который был в состоянии представить все символы. Буква "A" имела бы код 65, пробелом был бы код 32, и т.п. Данные символы могли быть удобно сохранены в 7 битах. Большинство компьютеров в те дни использовало 8-битовые регистры, и таким образом вы не только могли хранить любой возможный символ ASCII, но еще и имели целый бит экономии, который, если у вас была такая блажь, вы могли использовать в ваших собственных целях. Коды меньше 32 назывались непечатными и использовались для управляющих символов, например, символ 7 заставлял ваш компьютер издать сигнал динамика, а символ 12 являлся символом конца страницы, заставляя принтер прокрутить текущий лист бумаги и загрузить новый.
Поскольку байты имеют восемь битов, то многие думали: "мы можем использовать коды 128-255 в наших собственных целях". Неприятность была в том, что для очень многих эта идея пришла почти одновременно, но у всех были свои собственные идеи относительно того, что должно размещаться на месте с кодами от 128 до 255. У IBM-PC было нечто, что стало известным как набор символов OEM, в котором было немного диакритических символов для европейских языков и набор символов для рисования линий: горизонтальные полоски, вертикальные полоски, уголки, крестики, и т.д. И вы могли использовать эти символы для того, чтобы делать элегантные кнопки и рисовать линии на экране, которые вы все еще можете увидеть на некоторых старых компьютерах. Например, на некоторых PC символ с кодом 130 показывался как e, но на компьютерах, проданных в Израиле, это была еврейская буква Gimel (?). Если бы американцы посылали свои resume (резюме) в Израиль, они прибывали бы как r?sum?. Во многих случаях, как, например, в случае русского языка, было много различных идей относительно того, что делать с верхними 128 символами, и поэтому вы не могли даже надежно обмениваться русскоязычными документами.
В конечном счете, разнообразие кодировок OEM было сведено в стандарт ANSI. Стандарт ANSI, оговаривал, какие символы располагались ниже 128, эта область в основном оставалась той же, что и в ASCII, но было много различных способов обращаться с символами от 128 и выше в зависимости от того, где вы жили. Эти различные системы назвали кодовыми страницами. Так, например, в Израиле DOS использовал кодовую страницу с номером 862, в то время как греческие пользователи использовали страницу с номером 737. Они были одними и теми же ниже 128, но отличались от 128, где и находились все эти символы. Национальные версии MS-DOS поддерживали множество этих кодовых страниц, обращаясь со всеми языками, начиная с английского и заканчивая исландским, и было даже несколько "многоязычных" кодовых страниц, которые могли сделать Эсперанто и Галисийский (прим. пер.:галисийский язык относится к романской группе языков, распространён в Испании, носителей 4 млн. чел) на одном и том же компьютере! Но получить, скажем, иврит и греческий на одном и том же компьютере было абсолютно невозможно, если только вы не написали вашу собственную программу, которая показывала все, используя графику с побитовым отображением, потому что для еврейского и греческого требовались различные кодовые страницы с различными интерпретациями старших чисел.
Тем временем в Азии, принимая во внимание тот факт, что азиатские алфавиты имеют тысячи букв, которые никогда бы не смогли уместиться в 8 битов, эта проблема решалась запутанной системой DBCS, "двухбайтовый набор символов" (double byte character set), в котором некоторые символы сохранялись в одном байте, а другие занимали два. Было очень легко передвигаться по строке вперед, но абсолютно невозможно передвигаться назад. Программисты не могли использовать для перемещения вперед и назад s++ и s--, и вместо этого должны были вызывать специальные функции, которые знали, как иметь дело с этим беспорядком.
Тем не менее, большинство людей закрывало глаза на то, что байт был символом и символ был 8 битами и, пока вам не приходилось перемещать строку с одного компьютера на другой, или если вы не говорили больше, чем на одном языке, это работало. Но, конечно, как только массово стал использоваться Интернет, стало весьма обычным делом переносить строки с одного компьютера на другой. Хаос в этом вопросе был преодолен с помощью Unicode.
Unicode
Unicode был смелой попыткой создать единственный набор символов, который включал бы все реальные системы письма, существующие на планете, а также некоторые выдуманые. Некоторые люди имеют неправильное представление, что Unicode – это обычный 16-битовый код, где каждый символ занимает 16 битов и поэтому есть 65,536 возможных символов. На самом деле это не верно. Это самый распространенное ошибочное представление о Unicode.
Фактически, Unicode содержит необычный подход к пониманию понятия символ. До сих пор мы предполагали, что символы отображаются на набор каких-то битов, которые вы можете хранить на диске или в памяти:
A -> 0100 0001В Unicode символ отображается на нечто, называемое кодовой точкой (code point), которая является всего лишь теоретическим понятием. Как эта кодовая точка представлена в памяти или на диске — это отдельная история. В Unicode буква A это всего лишь платонова идея (эйдос) (прим. пер.: понятие философии Платона, эйдосы – это идеальные сущности, лишённые телесности и являющиеся подлинно объективной реальностью, находящиеся вне конкретных вещей и явлений).
A Эта платонова A отличается от B, и отличается от a, но это та же самая A, что и A и A. Идея, что А в шрифте Times New Roman является тем же самым, что и А в шрифте Helvetica, но отличается от строчной "a", не кажется слишком спорной в понимании людей. Но с точки зрения компьютерных наук и с точки зрения языка само определение буквы противоречиво. Немецкая буква ß – это настоящая буква или всего лишь причудливый способ написать ss? Если написание буквы, стоящей в конце слова, изменяется, она становится другой буквой? Иврит говорит да, арабский говорит нет. Так или иначе, умные люди в консорциуме Unicode поняли это, после большого количества политических дебатов, и вы не должны волноваться об этом. Все уже понято до нас.Каждой платоновой букве в каждом алфавите консорциумом Unicode было назначено волшебное число, которое записывается так, как это: U+0645. Это волшебное число называют кодовой точкой. U+ означает "Unicode", а числа являются шестнадцатеричными. Число U+FEC9 является арабской буквой Аин (Ain). Английская буква A соответствует U+0041.
В действительности нет никакого предела для количества букв, которые могут определяться через Unicode, и на самом деле они уже перешагнули за пределы 65,536, так что не каждая буква из Unicode может действительно сжиматься в два байта.

Для кириллицы в UNICODE отведен диапазон кодов от 0x0400 до 0x04FF. В данной таблице приведена лишь часть знаков этого диапазона, однако стандартом определено большинство кодов этого диапазона.
Представим, что мы имеем строку:
Привет!
U+041F U+0440 U+0438 U+0432 U+0435 U+0442 U+0021
Всего лишь набор кодовых точек. Числа в действительности.
Чтобы узнать, как будет выглядеть текстовый файл в формате Unicode, можно запустить программу notepad в Windows, вставить данную строку и при сохранении текстового файла выбрать кодировку Unicode.

Программа предлагает сохранение в трех разновидностях кодировок Unicode. Первый вариант представляет собой способ записи с младшим байтом впереди (little endian), второй со старшим байтом впереди (big endian). Какой из вариантов является правильным?
Вот как выглядит дамп файла со строкой “Привет!”, сохраненный в формате Unicode (big endian):

А так выглядит дамп файла со строкой “Привет!”, сохраненный в формате Unicode (little endian):

А так выглядит дамп файла со строкой “Привет!”, сохраненный в формате Unicode (UTF-8):

Ранние реализации хотели быть в состоянии хранить кодовые точки Unicode в формате с первым старшим байтом и первым младшим байтом (high-endian or low-endian), в зависимости от того, с каким форматом именно их процессор работал быстрее. Тогда возникло два способа хранить Unicode. Это привело к появлению причудливого соглашения о хранении кода \uFFFE в начале каждой строки Unicode. Эту сигнатуру называют меткой порядка байтов (byte order mark). Если вы поменяете местами ваши старший и младший байты, то в начале должно стоять \uFFFE, и человек, читающий вашу строку, будет знать, что он должен поменять байты в каждой паре местами. Данная сигнатура является зарезервированной в стандарте Unicode.
В стандарте Unicode написано, что порядок байт по умолчанию является либо big endian, либо little endian. Действительно, оба порядка являются правильным, и разработчики систем сами выбирают себе один из них. Не стоит беспокоиться, если ваша система обменивается данными с другой системой и обе используют little endian.
Однако, если ваша Windows обменивается данными с UNIX-сервером, который использует big endian, одна из систем должна осуществлять перекодировку. В этом случае стандарт Unicode гласит, что можно выбрать любой из следующих способов решения проблемы:
- Когда две системы, использующие различный порядок представления байт в Unicode, обмениваются данными (не используя каких-то специальных протоколов), то порядок байт должен быть big endian. В стандарте это называется каноническим (canonical) порядком байт.
- Каждая строка Unicode должна начинаться с кода \uFEFF. Код \uFFFE, который является “перевертыванием” знака порядка. Поэтому если получатель видит в качестве первого символа код \uFEFF, то это значит, что байты находятся в перевернутом (little endian) порядке. Тем не менее, в реальности, не каждая строка Unicode имеет в начале метку порядка байтов.
Второй способ является более универсальным и предпочтительным.
Некоторое время казалось, что все довольны, но англоязычные программисты рассматривали в основном английский текст и редко использовали кодовые точки выше U+00FF. По одной только этой причине Unicode многими игнорировался в течение нескольких лет.
Специально для этого была изобретена блестящая концепция UTF-8.
UTF-8
UTF-8 был другой системой хранения вашей последовательности кодовых точек Unicode, тех самых U+ чисел, используя те же 8 битов в памяти. В UTF-8 каждая кодовая точка с номерами от 0 до 127 сохранялись в единственном байте.
По сути, это кодировка с переменным количеством кодирующих байтов для хранения используется 2, 3, и, фактически, до 6 байтов. Если символ принадлежит набору ASCII (код в интервале 0x00-0x7F), то он кодируется так же как в ASCII одним байтом. Если юникод символа больше или равен 0x80, то его биты упаковываются в последовательность байтов по следующему правилу:
| Интервал Unicode (шестнадцатиричный) | Код UTF-8 (двоичный) |
| 0x0000 – 0x007F | 0xxxxxxx |
| 0x0080 – 0x07FF | 110xxxxx 10xxxxxx |
| 0x0800 – 0xFFFF | 1110xxxx 10xxxxxx 10xxxxxx |
Можно заметить, что если байт начинается с нулевого бита, то это однобайтовый символ ASCII. Если байт начинается с 11…, то это стартовый байт несколькобайтовой последовательности, кодирующей символ, число головных единичек которого равно количеству байт в последовательности. Если байт начинается с 10…, то это серийный «транспортный» байт из последовательности байтов, количество которых было определено стартовым байтом. Ну а биты Unicode символа упаковываются в «транспортные» биты стартового и серийных байтов, обозначенные в таблице как последовательность «xx..x».
В переменном количестве кодирующих байт можно убедиться по нижеприведенному дампу файлов.
Дамп файла со строкой “Hello!”, сохраненный в формате Unicode (UTF-8):

Дамп файла со строкой “Привет!”, сохраненный в формате Unicode (UTF-8):

Приятным побочным эффектом этого является то, что английский текст выглядит в UTF-8 точно то же, как и в ASCII, таким образом американцы даже не замечают, что что-то не так. Только вся остальная часть мира должна преодолевать препятствия. Конкретно, Hello, то, которое было U+0048 U+0065 U+006C U+006C U+006F, теперь будет сохранено в тех же 48 65 6C 6C 6F, так же как и в ASCII, и ANSI, и любом другом наборе символов OEM на планете. Если же вы столь смелы, чтобы использовать диакритические символы или греческие буквы или буквы Klingon, вы должны будете использовать несколько байтов для хранения единственной кодовой точки, но американцы никогда этого не заметят. UTF-8 также имеет хорошую особенность: старый код, неосведомленный о новом формате строк, и обрабатывающий строки с нулевом байтом в конце строки, не будет усекать строки.
Другие кодировки Unicode
Возвратимся к трем способам кодировать Unicode. Традиционные методы "хранить это в двух байтах" называют UCS-2 (потому что это имеет два байта) или UTF-16 (потому что это имеет 16 битов), и вы еще должны выяснять, является ли это код UCS-2 со старшим байтом в начале или со старшим байтом в конце. И есть популярный стандарт UTF-8, строки на котором имеют приятную особенность также работать и в старых программах, работающих с английским текстом, и в новых умных программах, которые прекрасно оперируют другими наборами символов, кроме ASCII.
На самом деле есть еще целый набор других способов закодировать Unicode. Есть нечто, называемое UTF-7, которое сильно походит на UTF-8, но гарантирует, что старший бит всегда будет нолем. Еще есть UCS-4, который хранит каждую кодовую точку в 4 байтах и гарантирует, что абсолютно все символы будут сохранены в одинаковом числе байтов, но такая трата памяти впустую не всегда оправдана такой гарантией.
Например, вы можете закодировать в Unicode строку Hello (U+0048 U+0065 U+006C U+006C U+006F) в кодировке ASCII, или в старой греческой кодировке OEM, или в еврейской кодировке ANSI, или в любой из нескольких сотен кодировок, которые были изобретены до наших дней, с одной проблемой: некоторые из символов могут не отображаться! Если нет никакого эквивалента для кодовой точки Unicode, для которой вы пытаетесь найти эквивалент в какой-либо кодовой таблице, для которой вы пытаетесь сделать преобразование, вы обычно получаете небольшой вопросительный знак: ? или, если вы действительно хороший программист, то квадратик.
Есть сотни традиционных кодировок, которые могут правильно хранить только некоторые кодовые точки и заменять все остальные кодовые точки вопросительными знаками. Например, некоторые популярные кодировки английского текста - Windows 1252 (стандарт Windows 9x для западноевропейских языков) и ISO-8859-1, он же Латинский-1 (также пригодный для любого западноевропейского языка). Но попытайтесь преобразовать русские или еврейские буквы в этих кодировках, и вы получите изрядное количество вопросительных знаков. Отличной чертой UTF 7, 8, 16, и 32 является их способность правильно хранить любую кодовую точку.
32 битные кодовые точки для символов Unicode в Java
В версию Java 2 5.0 внесены значительные дополнения в типы Character и String для поддержки 32 битных символов Unicode. В прошлом все символы Unicode могли храниться в шестнадцати битах, которые равны размеру значения типа char (и размеру значения, содержащегося в объекте типа Character), поскольку эти значения лежали в диапазоне от 0 до FFFF. Но с некоторого времени набор символов Unicode был расширен, и теперь требует больше 16 бит для хранения символа. Новая версия наборов символов Unicode включает в себя символы, лежащие в диапазоне от 0 до 10FFFF.
Кодовая точка или позиция (code point), кодовая единица или кодовое значение (code unit) и дополнительный символ (supplemental character). Применительно к языку Java кодовая точка — это код символа из диапазона от 0 до 10FFFF. В языке Java термин “кодовая единица” используется для ссылки на 16-битные символы. Символы, имеющие значения, большие, чем FFFF, называются дополнительными.
Расширение набора символов Unicode создало фундаментальные проблемы для языка Java. Поскольку у дополнительного символа значение больше, чем может вместить тип char, потребовались некоторые средства для хранения и обработки дополнительных символов. В версии Java 2 5.0 эта проблема решена двумя способами. Во-первых, язык Java использует два значения типа char для представления дополнительного символа. Первое из них называется верхним суррогатом (high surrogate), а второе – нижним суррогатом (low surrogate). Разработаны новые методы, такие как codePointAt(), для преобразований кодовых точек в дополнительные символы и обратно.
Во-вторых, в языке Java перегружены некоторые из существовавших ранее методов в классах Character и String. В перегруженных вариантах методов используются данные типа int вместо char. Поскольку размер переменной или константы типа int достаточно велик для размещения любого символа как единичного значения, этот тип может использоваться для хранения любого символа. Например, у метода isDigit() теперь два варианта, приведенные далее:
Первый из приведенных вариантов – первоначальный, второй – версия, поддерживающая 32-битные кодовые точки. У всех методов is …, таких как isLetter() и isSpaceChar(), есть версии для кодовых точек, как и у методов to …, таких как toUpperCase() и toLowerCase().
В дополнение к методам, перегруженных для обработки кодовых точек, в язык Java, в класс Character включены новые методы, обеспечивающие дополнительную поддержку кодовых точек. Некоторые из них перечислены в таблице:
| Метод | Описание |
| static int charCount(int cp) | Возвращает 1, если cp можно представить одним значением типа char. Возвращает 2, если требуется два значения типа char. |
| static int codePointAt(CharSequence chars, int loc) | Возвращает кодовую точку для символьной позиции (location), заданной в параметре loc |
| static int codePointAt(char[] chars, int loc) | Возвращает кодовую точку для символьной позиции (location), заданной в параметре loc |
| static int codePointBefore(CharSequence chars, int loc) | Возвращает кодовую точку для символьной позиции (location) предшествующей заданной в параметре loc |
| static int codePointBefore(char[] chars, int loc) | Возвращает кодовую точку для символьной позиции (location) предшествующей заданной в параметре loc |
| static boolean isSupplementaryCodePoint(int cp) | Возвращает true, если cp содержит дополнительный символ |
| static boolean isHighSurrogate(char ch) | Возвращает true, если ch содержит допустимый верхний суррогат символа. |
| static boolean isLowSurrogate(char ch) | Возвращает true, если ch содержит допустимый нижний суррогат символа. |
| static boolean isSurrogatePair(char highCh, char lowCh) | Возвращает true, если highCh и lowCh формируют допустимую суррогатную пару. |
| static boolean isValidCodePoint(int cp) | Возвращает true, если cp содержит допустимую кодовую точку. |
| static char[] toChars(int cp) | Преобразует кодовую точку, содержащуюся в cp, в ее эквивалент типа char, который может потребовать двух значений типа char. Возвращает массив, содержащий результат … Дописать!!! |
| static int toChars(int cp, char target[], int loc) | Преобразует кодовую точку, содержащуюся в cp, в ее эквивалент типа char, запоминает результат в массиве target, начиная с позиции, заданной в loc. Возвращает 1, если cp можно представить одним значением типа char, и 2 в противном случае. |
| static int toCodePoint(char ighCh, char lowCh) | Преобразует highCh и lowCh в их эквивалентные кодовые точки. |
Для обработки кодовых точек у класса String есть ряд методов. В класс String также добавлен приведенный далее конструктор, поддерживающий расширенный набор символов Unicode:
String(int[] codePoints, int startIndex, int numChars)
В приведенной синтаксической записи codePoints – это массив, содержащий кодовые точки. Формируется результирующая строка протяженностью numChars, начиная с позиции startIndex.
Некоторые методы класса String, обеспечивающие поддержку 32-битных кодовых точек для символов Unicode.
| Метод | Описание |
| int codePointAt(int i) | Возвращает кодовую точку для позиции в строке, заданной параметром i |
| int codePointBefore(int i) | Возвращает кодовую точку для позиции в строке, предшествующей заданной параметром i |
| int codePointCount(int start, int end) | Возвращает количество кодовых точек в порции вызывающей строки, расположенной между символьными порциями start и end-1 |
| int offsetByCodePoints(int start, int num) | Возвращает позицию в вызывающей строке, расположенную на расстоянии num кодовых точек после начальной позиции, заданной параметром start |
Вывод на консоль в Windows. Команда chcp
Большинство простых программ, написанных на Java выводят какие-либо данные на консоль. Вывод на консоль предоставляет возможность выбрать кодировку, в которой будут выводиться данные вашей программы. Запустить окно консоли можно нажав Пуск -> Выполнить, а затем ввести и запустить команду cmd. Вывод на консоль в Windows по умолчанию производится в кодировке Cp866. Чтобы узнать в какой кодировке выводятся символы в консоли, следует набрать команду chcp. С помощью этой же команды можно задавать кодировку, в которой будут выводиться символы. Например chcp 1251. Фактически данная команда создана только для того, чтобы отражать или изменять номер текущей кодовой страницы консоли.
Кодовые страницы, отличные от Cp866 будут правильно отображаться только в полноэкранном режиме или в окне командной строки, использующем шрифты TrueType. Например:
Для того, чтобы увидеть последующий вывод, необходимо сменить текущий шрифт на шрифт True Type. Подведите курсор на заголовок окна консоли, щелкните правой кнопкой мыши и выберите опцию “Свойства”. В появившемся окне перейдите вкладку Шрифт и в ней выберите шрифт, напротив которого будет стоять двойная буква Т. Вам будет предложено сохранить данную настройку для текущего окна или для всех окон.

В итоге ваше окно консоли примет вид:

Таким образом, манипулируя данной командой можно видеть результаты вывода вашей программы в зависимости от кодировки.
Системные свойства file.encoding, console.encoding и вывод на консоль
Прежде чем затрагивать тему кодировок в исходных кодах программ следует четко уяснить, для чего предназначены, и как работают системные свойства file.encoding и console.encoding. Кроме этих системных свойств присутствует еще ряд других. Вывести на экран все текущие системные свойства можно с помощью следующей программы:
import java.io.*;
import java.util.*;
public class getPropertiesDemo
{
public static void main(String args[])
{
String s;
for (Enumeration e = System.getProperties().propertyNames(); e.hasMoreElements() ;)
{
s = e.nextElement().toString();
System.out.println(s+"="+System.getProperty(s));
}
}
}
Пример вывода программы:

В операционной системе Windows по умолчанию file.encoding=Сp1251. Однако существует еще одно свойство console.encoding, которое указывает, в какой кодировке следует производить вывод на консоль. file.encoding указывает Java машине в какой кодировке следует считывать исходные коды программ, если кодировка не указана пользователем при компиляции. Фактически, данное системное свойство распространяется и на вывод с помощью System.out.println().
По умолчанию данное свойство не установлено. Эти системные свойства можно устанавливать и в вашей программе, однако, для нее это уже будет не актуально, поскольку виртуальная машина пользуется теми значениями, которые были считаны перед компиляцией и запуском вашей программы. Кроме того, как только ваша программа отрабатывает, системные свойства восстанавливаются. В этом можно убедиться, запустив дважды следующую программу.
/**
* @author <a; href="mailto:[email protected]"> Victor Zagrebin </a>
*/
public class SetPropertyDemo
{
public static void main(String[] args)
{
System.out.println("file.encoding before="+System.getProperty("file.encoding"));
System.out.println("console.encoding before="+System.getProperty("console.encoding"));
System.setProperty("file.encoding","Cp866");
System.setProperty("console.encoding","Cp866");
System.out.println("file.encoding after="+System.getProperty("file.encoding"));
System.out.println("console.encoding after="+System.getProperty("console.encoding"));
}
}

Установка данных свойств в программе необходима в тех случаях, когда оно используется в последующем коде до завершения работы программы.
Воспроизведем еще ряд типичных примеров, с проблемами, которыми сталкиваются программисты при выводе. Допустим, у нас есть следующая программа:
public class CyryllicDemo
{
public static void main(String[] args)
{
String s1 = "АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЬЫЪЭЮЯ";
String s2 = "абвгдежзийклмнопрстуфхцчшщьыъэюя";
System.out.println(s1);
System.out.println(s1);
}
}
- команда компиляции;
- команда запуска;
- кодировка исходного кода программы (устанавливается в большинстве текстовых редакторов);
- кодировка вывода на консоль (Используется Cp866 по умолчанию или устанавливается с помощью команды
chcp) ; - видимый вывод в окне консоли.
javac CyryllicDemo.java
java CyryllicDemo
Кодировка файла: Cp1251
Кодировка консоли: Cp866
Вывод:
└┴┬├─┼╞╟╚╔╩╦╠═╬╧╨╤╥╙╘╒╓╫╪┘▄█┌▌▐▀
рстуфхцчшщъыьэюяЁёЄєЇїЎў°∙№√·¤■
javac CyryllicDemo.java
Кодировка файла: Cp866
Кодировка консоли: Cp866
Вывод:
CyryllicDemo.java:5:
warning: unmappable character for encoding Cp1251
String s1 = "АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧ?ЩЬЫЪЭЮЯ";
^
javac CyryllicDemo.java -encoding
Cp866
java -Dfile.encoding=Cp866
CyryllicDemo
Кодировка файла: Cp866
Кодировка консоли: Cp866
Вывод:
АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЬЫЪЭЮЯ
абвгдежзийклмнопрстуфхцчшщьыъэюя
javac CyryllicDemo.java -encoding
Cp1251
java -Dfile.encoding=Cp866
CyryllicDemo
Кодировка файла: Cp1251
Кодировка консоли: Cp866
Вывод:
АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЬЫЪЭЮЯ
абвгдежзийклмнопрстуфхцчшщьыъэюя
Особо следует обратить внимание на проблему “Куда делась буква Ш ?” из второй серии запусков. Еще внимательнее к этой проблеме следует относиться, если вы заранее не знаете, какой текст будет храниться в выводимой строке, и по наивности сделаете компиляцию без задания кодировки. Если у вас действительно в строке не будет буквы Ш, то компиляция выполнится удачно и запуск тоже. И на этом вы даже забудете, что упускаете мелочь (букву Ш), которая может потенциально встретиться в выводимой строке и неизбежно приведет к дальнейшим ошибкам.
В третьей и четвертой серии при компиляции и запуске используются ключи: -encoding Cp866 и -Dfile.encoding=Cp866. Ключ -encoding указывает, в какой кодировке следует считывать файл с исходным кодом программы. Ключ -Dfile.encoding=Cp866 указывает в какой кодировке следует производить вывод.
Unicode префикс \u и русские символы в исходных кодах
В языке Java для записи символов в формате Unicode существует специальный префикс \u, а следующие за ним четыре шестнадцатиричные цифры задают сам символ. Например, \u2122 – это символ торговой марки (™). Такая форма записи выражает символ любого алфавита с помощью цифр и префикса – символов, которые содержатся в стабильном диапазоне кодов от 0 до 127, который не затрагивается при перекодировке исходного кода. И, теоретически, в приложении или аплете на языке Java можно использовать любой символ в формате Unicode, однако будет ли он отображаться корректно на экране дисплея и, будет ли он отображаться вообще, зависит от многих факторов. Для аплетов имеет значение тип браузера, а для программ и аплетов имеет значение тип операционной системы и кодировка, в которой написан исходный код программы.
Например, на компьютерах, работающих под управлением американской версии системы Windows, с помощью языка Java невозможно отобразить японские иероглифы из-за вопроса интернационализации.
В качестве второго примера можно привести вполне частую ошибку программистов. Многие думают, что задание русских символов в Unicode формате с помощью префикса \u в исходном коде программы может решить проблему вывода русских символов при любых обстоятельствах. Ведь виртуальная машина Java переводит исходный код программы в Unicode. Однако прежде чем осуществить перевод в Unicode виртуальная машина должна знать, в какой кодировке написан исходный код вашей программы. Ведь вы можете написать программу и в кодировке Cp866 (DOS) и в Сp1251 (Windows), что типично для данной ситуации. В том случае, если вы не указали кодировки, виртуальная машина Java считывает ваш файл с исходным кодом программы в той кодировке, которая указана в системном свойстве file.encoding.
Однако вернемся к параметрам по умолчанию, и будем считать что file.encoding=Сp1251, а вывод на консоль производится в Cp866. Вот именно в этом случае выходит следующая ситуация: допустим у вас есть файл в кодировке Сp1251:
Файл MsgDemo1.java
public class MsgDemo1
{
public static void main(String[] args)
{
String s = "\u043A\u043E"+
"\u0434\u0438\u0440\u043E\u0432"+
"\u043A\u0430";
System.out.println(s);
}
}
И вы ожидаете, что на консоль выведется слово “кодировка”, однако получаете:

Дело в том, что коды с префиксом \u, перечисленные в программе действительно кодируют нужные кириллические символы в кодовой таблице Unicode, однако они рассчитаны на то, что исходный код вашей программы будет считан в кодировке Cp866 (DOS). По умолчанию, же в системных свойствах указана кодировка Сp1251 (file.encoding=Сp1251). Естественно, первое и неправильное, что приходит на ум – поменять кодировку файла с исходным кодом программы в текстовом редакторе. Но это ни к чему не приведет. Виртуальная машина Java все равно будет считывать ваш файл в кодировке Сp1251, а коды \u рассчитаны на Cp866.
Из этой ситуации есть три выхода. Первый вариант – использовать ключ -encoding на этапе компиляции и –Dfile.encoding на этапе запуска программы. В этом случае вы принудительно указываете виртуальной машине Java, чтобы она считывала файл с исходным кодом в заданной кодировке и выводила в заданной кодировке.

Как видно из вывода на консоли, при компиляции должен задаваться дополнительный параметр –encoding Cp866, а при запуске должен задаваться параметр –Dfile.encoding=Cp866.
Второй вариант заключается в том, чтобы перекодировать символы в самой программе. Он предназначен для восстановления верных кодов букв, если они были неверно проинтерпретированы. Суть метода проста: из полученных неверных символов, используя соответствующую кодовую страницу, восстанавливается исходный массив байтов. Затем из этого массива байтов, используя уже корректную страницу, получаются нормальные коды символов.
Для преобразования потока байт byte[] в строку String и обратно, в классе String есть следующие возможности: конструктор String(byte[] bytes, String enc), который получает на вход поток байт с указанием их кодировки; если кодировку опустить, то она будет принята кодировка по умолчанию из системного свойства file.encoding. Метод getBytes(String enc) возвращает поток байт, записанных в указанной кодировке; кодировку также можно опустить и будет принята кодировка по умолчанию из системного свойства file.encoding.
Пример:
Файл MsgDemo2.java
import java.io.UnsupportedEncodingException;
public class MsgDemo2
{
public static void main(String[] args) throws UnsupportedEncodingException
{
String str = "\u043A\u043E"+
"\u0434\u0438\u0440\u043E\u0432"+
"\u043A\u0430";
byte[] b = str.getBytes("Cp866");
String str2 = new String(b,"Cp1251");
System.out.println(str2);
}
}
Результат вывода программы:

Этот способ является менее гибким в том случае, если вы ориентируетесь на то, что кодировка в системном свойстве file.encoding не изменится. Однако этот способ может стать самым гибким, если проводить опрос системного свойства file.encoding, и подставлять полученное значение кодировки при формировании строк в вашей программе. При использовании данного способа следует внимательно относиться к тому, что не все страницы выполняют однозначное преобразование byte <-> char.
Третий способ заключается в том, чтобы подобрать корректные Unicode коды для вывода слова “кодировка” из расчета, что файл будет считываться в кодировке по умолчанию – Cp1251. Для этих целей существует специальная утилита native2ascii.
Эта утилита входит в состав Sun JDK и предназначена для преобразования исходных текстов к ASCII-виду. При запуске без параметров, работает со стандартным входом (stdin), а не выводит подсказку по ключам, как остальные утилиты. Это приводит к тому, что многие и не догадываются о необходимости указания параметров (кроме, тех, кто заглянул в документацию). Между тем этой утилите для правильной работы необходимо, как минимум, указать используемую кодировку с помощью ключа -encoding. Если этого не сделать, то будет использована кодировка по умолчанию (file.encoding), что может несколько расходится с ожидаемой. В результате, получив неверные кода букв (из-за неверной кодировки), можно потратить много времени на поиск ошибок в абсолютно верном коде.
Следующий скриншот показывает различие в последовательностях Unicode кодов для одного и того же слова, если исходный файл будет считываться в кодировке Cp866 и в кодировке Cp1251.

Таким образом, если вы принудительно не указываете кодировки для виртуальной машины Java при компиляции и при запуске, а кодировкой по умолчанию (file.encoding) является Cp1251, то исходный код программы должен выглядеть следующим образом:
Файл MsgDemo3.java
public class MsgDemo3
{
public static void main(String[] args)
{
String s = "\u0404\u00AE"+
"\u00A4\u0401\u0430\u00AE\u045E"+
"\u0404\u00A0";
System.out.println(s);
}
}

Использовав третий способ, можно сделать вывод: если кодировка файла с исходным кодом в редакторе совпала с кодировкой в системе, то сообщение “кодировка” появится в нормальном виде.
Чтение и запись в файл русских символов, выраженных Unicode префиксом \u
Для чтения данных, записанных как в формате MBCS (используя кодировку UTF-8), так и в формате Unicode, можно использовать класс InputStreamReader из пакета java.io, подставляя в его конструктор различные кодировки. Для записи используется OutputStreamWriter. В описании пакета java.lang написано, что каждая реализация JVM поддерживет следующие кодировки:
| Название кодировки | Описание |
| US-ASCII | семибитная ASCII, она же ISO646-US, она же основная латинская часть Unicode; |
| ISO-8859-1 | то же самое, что ISO-LATIN-1; |
| UTF-8 | 8-битный; |
| UTF-16BE | 16-битный, порядок байт big-endian; |
| UTF-16LE | 16-битный, порядок байт little-endian; |
| UTF-16 | 16-битный, порядок байт определяется начальными значениями (допускается любой), на выходе порядок байт big-endian. |
Файл WriteDemo.java
import java.io.Writer;
import java.io.OutputStreamWriter;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* Вывод Unicode строки в файл в заданной кодировке.
* @author <a; href="mailto:[email protected]"> Victor Zagrebin </a>
*/
public class WriteDemo
{
public static void main(String[] args) throws IOException
{
String str = "\u043A\u043E"+
"\u0434\u0438\u0440\u043E\u0432"+
"\u043A\u0430";
Writer out1 = new OutputStreamWriter(new FileOutputStream("out1.txt"), "Cp1251");
Writer out2 = new OutputStreamWriter(new FileOutputStream("out2.txt"), "Cp866");
Writer out3 = new OutputStreamWriter(new FileOutputStream("out3.txt"), "UTF-8");
Writer out4 = new OutputStreamWriter(new FileOutputStream("out4.txt"), "Unicode");
out1.write(str);
out1.close();
out2.write(str);
out2.close();
out3.write(str);
out3.close();
out4.write(str);
out4.close();
}
}
javac WriteDemo.java
java WriteDemo
В результате выполнения программы должно создаться четыре файла (out1.txt out2.txt out3.txt out4.txt) в каталоге запуска программы, каждый из которых будет содержать слово “кодировка” в разной кодировке, что можно проверить в текстовых редакторах или с помощью просмотра дампа файла.
Следующая программа будет считывать и выводить на экран содержимое каждого из созданных файлов.
Файл ReadDemo.java
import java.io.Reader;
import java.io.InputStreamReader;
import java.io.InputStream;
import java.io.FileInputStream;
import java.io.IOException;
/**
* Чтение Unicode символов из файла в заданной кодировке.
* @author <a; href="mailto:[email protected]"> Victor Zagrebin </a>
*/
public class ReadDemo
{
public static void main(String[] args) throws IOException
{
String out_enc = System.getProperty("console.encoding","Cp866");
System.out.write(readStringFromFile("out1.txt", "Cp1251", out_enc));
System.out.write('\n');
System.out.write(readStringFromFile("out2.txt", "Cp866", out_enc));
System.out.write('\n');
System.out.write(readStringFromFile("out3.txt", "UTF-8", out_enc));
System.out.write('\n');
System.out.write(readStringFromFile("out4.txt", "Unicode", out_enc));
}
public static byte[] readStringFromFile(String filename,
String file_enc,
String out_enc) throws IOException
{
int size;
InputStream f = new FileInputStream(filename);
size = f.available();
Reader in = new InputStreamReader(f,file_enc);
char ch[] = new char[size];
in.read(ch,0,size);
in.close();
return (new String(ch)).getBytes(out_enc);
}
}
javac ReadDemo.java
java ReadDemo

Особо следует отметить использование следующей строки кода в данной программе:
String out_enc = System.getProperty("console.encoding","Cp866");
С помощью метода getProperty осуществляется попытка прочитать значение системного свойства console.encoding, которое задает кодировку, в которой будут выводиться данные на консоль. Если же такое свойство не установлено (зачастую оно не установлено), то переменной out_enc присвоится "Cp866". И далее, переменная out_enc используется там, где необходимо привести считанную из файла строку к кодировке, пригодной для вывода на консоль.
Также возникает закономерный вопрос: “почему используется System.out.write, а не System.out.println” ? Как было описано выше, системное свойство file.encoding используется не только для считывания исходного файла, а и для вывода с помощью System.out.println, что в данном случае приведет к некорректному выводу.
Неправильное отображение кодировки в программах, ориентированных на web
Программисту прежде всего следует знать: не имеет смысла иметь строку, не зная, какую кодировку она использует. Не существует такого понятия как "простой" (plain) текст в ASCII. Если у вас есть строка, в памяти, в файле, или в сообщении электронной почты, вы должны знать, в какой она кодировке, иначе вы не сможете ее правильно интерпретировать или показать пользователю.
Почти все традиционные проблемы типа "мой вебсайт похож на тарабарщину" или "мои электронные письма не читаются, если я использую символы с ударениями" лежат на ответственности программиста, который не понимает простого факта, что если вы не знаете в какой кодировке строка UTF-8 или ASCII или ISO 8859-1 (Латинский-1) или Windows 1252 (Западноевропейский), вы просто не сможете вывести ее правильно. Есть более ста кодировок символов выше кодовой точки 127, и нет никакой информации для того, чтобы выяснить, какая кодировка нужна. Как мы сохраняем информацию о том, какую кодировку используют строки? Существуют стандартные способы для указания этой информации. Для сообщений электронной почты вы должны поместить в HTTP заголовок строку
Content-Type: text/plain; charset="UTF-8"
Для веб-страницы оригинальная идея была в том, что веб-сервер сам будет посылать HTTP заголовок, перед самой страницей HTML. Но это вызывает определенные проблемы. Предположим, что вы имеете большой веб-сервер с большим количеством сайтов и сотнями страниц, созданных большим количеством людей на огромном количестве различных языков, и все они не используют специфическую кодировку. Сам веб-сервер действительно не может знать, какая кодировка у каждого файла, и поэтому не может послать заголовок с указанием Content-Type. Поэтому для указания правильной кодировки в http заголовке оставалось держать информацию о кодировке внутри html файла путем вставки специального тега. Сервер бы в таком случае считывал наименование кодировки из мета-тега и помещал ее в HTTP заголовок.
Возникает уместный вопрос: «как начать считывать файл HTML, пока Вы не узнаете, какую кодировку он использует?! К счастью, почти все кодировки используют одну и ту же таблицу символов с кодами от 32 до 127, и сам код HTML состоит из этих символов, и вы можете даже не встретить в html файле информацию о кодировке, если он полностью состоит из таких символов. Поэтому, в идеале, тег <meta;> с указанием кодировки действительно должен быть в самой первой строке в секции <head;>, потому что как только веб-браузер увидит этот признак, он перестанет разбирать страницу и начнет все заново, используя ту кодировку, которую вы задали.
<html;>
<head;>
<meta; http-equiv="Content-Type" content="text/html; charset=utf-8">
Что делают веб-браузеры, если они не находят никакого Content-Type, ни в заголовке http, ни в теге Meta? Internet Explorer фактически делает кое-что весьма интересное: он пробует распознать кодировку и язык, основываясь на частоте, с которой различные байты появляются в типичном тексте в типичных кодировках различных языков. Так как разные старые 8-байтовые кодовые страницы по-разному размещали национальные символы в диапазоне между 128 и 255, и так как все человеческие языки имеют различные частотные вероятности использования букв, такой подход часто неплохо срабатывает.
Это весьма причудливо, но это, кажется, действительно cрабатывает достаточно часто и наивные авторы веб-страниц, которые никогда не знали, что они нуждались в указании тэга Content-Type в заголовке их страничек для того, чтобы странички правильно отображались, до того прекрасного дня, когда они напишут что-то, что точно не соответствует типичному частотно-вероятностному распределению букв их родного языка, и Internet Explorer решит, что это корейский язык и покажет ее соответствующим образом.
Так или иначе, что остается делать читателю этого вебсайта, который был написан на болгарском языке, но отображается на корейском (и даже не на осмысленном корейском)? Он использует меню View | Encoding и пробует несколько разных кодировок (есть по крайней мере дюжина для восточноевропейских языков), пока картина не станет более ясной. Если, конечно, он знает, как это делать, ведь большинство людей этого не знает.
Стоит отметить, что для UTF-8, которая уже в течение многих лет прекрасно поддерживается веб-браузерами, еще никем не встречена проблема с правильным отображением веб-страниц.
Ссылки:
- Joel Spolsky. The absolute minimum every software developer absolutely, positively must know about Unicode and character sets (No Excuses!) 08.10.2003 http://www.joelonsoftware.com/articles/Unicode.html
- Сергей Астахов. Java: русские буквы и не только…
- Сергей Семихатов. Java и Unicode. 08.2000 - 27.07.2005
- Хорстман К.С., Корнелл Г. Библиотека профессионала. Java 2. Том 1. Основы. — М.: Издательский дом Вильямс, 2003. — 848 с
- Dan Chisholms. Java Programmer Mock Exams. Objective 2, InputStream and OutputStream Reader/Writer. Java Character Encoding: UTF and Unicode. http://www.jchq.net/certkey/1102_12certkey.htm
- Package java.io. JavaTM 2 Platform Standard Edition 6.0 API Specification. http://java.sun.com
- Unicode Standard, version 4.0. http://www.unicode.org



 Узнай о чем ты на самом деле сейчас думаешь
Узнай о чем ты на самом деле сейчас думаешь 

