
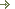
Способы переноса данных с помощью Pentaho Data Integration
Проблемы переноса данных между гетерогенными СУБД , как правило, можно ре-шить стандартными, штатными средствами, входящими в набор инструментариев для ра-боты с той или иной платформой баз данных. Однако в ряде случаев использование таких средств, не приводит к желаемым результатам. Это обусловлено в первую очередь разрас-танием корпоративной информационной системы и интеграцией в нее массивов данных, гетерогенных не только по типу СУБД, но и по способам организации физического хране-ния, например файловые структуры в различных форматах (текстовом или xml), а также по способам доступа к ней, например удаленные ftp, http – ресурсы. Промышленная экс-плуатация выдвигает ряд дополнительных требований к переносу структур данных в пер-вую очередь связанных с оперативностью получения необходимой информации, возмож-ностью гибкого изменения как ресурсов с которых необходимо получать данные, так и адаптация к возможным изменениям структуры получаемых данных.
Цель данной статьи, является анализ возможных способов адаптивной трансформа-ции данных с помощью серверных технологий Sun, которые де-факто стали промышлен-ными стандартами в области корпоративных информационных систем. Новизна данной работы заключается в использовании библиотек от фирмы Pentaho для интеграции данных и разработке на ее основе портальной системы на базе JBossportal и JBoss Application Server, позволяющей не только выполнять адаптивную трансформацию данных но и их анализ в режиме реального времени.
В нашей практике при решении задач связанных с трансформацией данных, мы, как правило, использовали два подхода. Основой для каждого подхода является уровень дан-ных системы, в которую нужно перенести информацию. Исходя из этого, в первом случае разрабатывается ряд запросов, в виде SQL- скриптов, с помощью которых осуществляется перенос данных на "прямую". Второй способ базируется на persistence – уровне бизнес объектов - структуры, в которую необходимо перенести данные. Этот уровень обычно разрабатывается либо с помощью Hibernate, либо ejb3. А бизнес объекты источника дан-ных получают практически в автоматическом режиме с помощью entity manger - ejb3. Да-лее логика трансформации реализуется в Java – коде.
Экспериментальные исследования выполнялись на тестовых СУБД. В качестве платформ использовались MS SQL Server 2000, MS SQL Server 2005, MySQLv5, Post-greSQL v8.2 в различных вариациях трансформации между ними. Размер тестовой схемы базы данных составлял около 400 Мб. При этом следует заметить, что тестирование вы-полняли в условиях максимально приближенных к промышленной эксплуатации, транс-формации выполнялись с удаленных, за сотни километров серверов в средине рабочего дня, когда корпоративные коммуникации максимально загружены. В связи c этим, разброс скорости трансформации по первому варианту составлял 8-20 минут по второму 15-40 минут. Таким образом, во временном диапазоне выполнения задачи, первый вариант вы-глядит более предпочтительным, однако с точки зрения корректности трансформации, он сильно проигрывает второму варианту, так как, используя механизмы Java, например па-раметризованные типы, можно должным образом корректировать несоответствия типов данных, обеспечивая платформенную независимость. Поэтому нами был выбран второй вариант, которым мы успешно пользовались в течении года. Следует отметить, что опи-санные выше способы имеют общие серьезные недостатки. Во-первых, они являются "не гибкими", т.е. малейшие изменения структуры бизнес объектов или источников данных, вынуждают кропотливо перерабатывать всю логику трансформации. Во-вторых, доволь-но трудоемкий процесс адаптации задач к гетерогенным источникам данных, а в первом случае он вообще не возможен. В-третьих, для привязки планировщика задач к выполне-нию трансформаций, фактически нужно реализовать с нуля специализированное прило-жение. В четвертых, зачастую, часть полученных данных используется один раз для вы-полнения комплексных отчетов с занесением соответствующих обработанных данных в соответствующие таблицы, поэтому целесообразна реализация в процессе трансформации подготовки данных для отчетов. Кроме того, излишние объемы хранимой информации, дополнительно нагружают СУБД. В пятых, создание новых трансформаций и редактиро-вание существующих подразумевает, чтобы аналитик, планирующий всевозможные отче-ты был в состоянии реализовать в коде всевозможные манипуляции для подготовки дан-ных, т.е. был квалифицированным программистом. Так же помимо редактирования суще-ствующих трансформаций, хотя бы раз в квартал, необходимо готовить отчет по новым требованиям и формам. Описанные выше факты, инициировали нас к поиску средства по-зволяющего решить описанные проблемы. Были сформулированы основные требования к данному средству:
- Наличие интуитивно понятного интерфейса, позволяющего используя drag and drop визуально составлять трансформации;
- Возможность работы с максимальным количеством СУБД и файловых структур, а так же источниками данных для их получения;
- По возможности низкая стоимость;
- Платформенная независимость;
- Наличие планировщика задач, позволяющего выполнять трансформации по распи-санию.
Среди систем, ориентированных на интеграцию данных (Data Integration System), на-пример, наиболее подходящим средством, удовлетворяющим, описанные выше требо-вания, является продукт фирмы Pentaho – Kettle, который по сравнению с аналогами явля-ется свободно распространяемым и имеет API - интерфейс, но при желании у разработчи-ков существует масса коммерческих решений. Название системы Kettle, является акрони-мом от английских слов Kettle Extraction, Transformation, Transportation and Loading of data Environment, таким образом, это среда для извлечения, трансформации, передачи и за-грузки данных. Помимо всего прочего компания pentaho занимается разработкой компо-нент с помощью которых можно создать полноценную Business Intelligence (BI) – систему, включающую OLAP средство Mondrian, а также мощное средство для создания отчетов. В данном случае нами рассматривалась только возможность интеграции данных, с перехо-дом в перспективе к полноценной BI – системе.
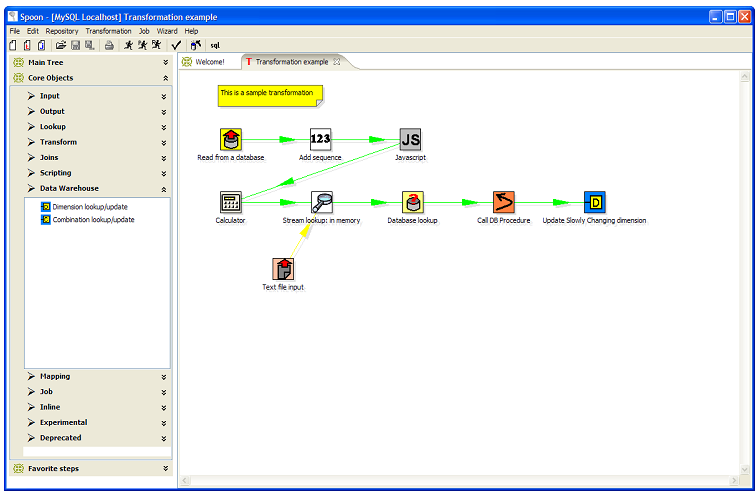
Рисунок 1. Интерфейс взаимодействия со средством для разработки трансформаций - Pan
Kettle представлен оболочкой Spoon, которая позволяет запускать "внутри" себя средства для создания трансформаций (transformations) Pan и работ ( jobs) Kitchen. А на-личие графического интерфейса позволяет, используя drag and drop, с помощью "мышки" довольно просто и быстро создавать трансформации и работы. Кроме того, в комплект по-ставки входит Web сервер Cart, позволяющий выполнять transformation и job удаленно. Наличие у job планировщика задач, позволяет выполнять его с помощью Cart по состав-ленному заранее расписанию.

Рисунок 2. Интерфейс взаимодействия со средством для разработки job - Kitchen
Первые тестовые трансформации показали довольно высокую скорость, время вы-полнение находилось в пределах от 20 секунд до одной минуты.
Следует заметить, что если механизм разработки объектов для трансформации дан-ных нас полностью устраивал, то средство планирования и отслеживание выполнения jobs, полностью не устраивало, из-за нестабильной работы, неудобной реализацией в не-коммерческом варианте продукта. Поэтому было принято решение реализовать возмож-ность планирования выполнения job с помощью библиотеки QUARTZа работающую в связке с сервером приложений JBoss. Клиентская часть была реализована в виде портле-тов. Система реализована в виде двух проектов, первый – обычное java – приложение, ко-торое может запускаться как в режиме standalone с параметрами из командной строки и позволяет удаленно выполнять трансформации так и из портлетов на стороне сервера приложений. Второй Web- приложение, в котором реализованы портлеты, которые вызы-вают методы первого приложения, входящего во второе в виде библиотеки. При таком подходе, очень удобно выполнять отладку на локальной машине.
Работа с библиотеками Kettle.jar имеет некоторые особенности. Трудности с кото-рыми мы столкнулись – отсутствие полноценной Javadoc, этот недостаток, к сожалению присущ большинству некоммерческих проектов. Поэтому до получения желаемых резуль-татов при работе с многочисленными методами классов библиотеки выполнялось множе-ство экспериментальных запусков в режиме отладчика. Из особенностей следует отме-тить, необходимость при начале работы с библиотекой, инициализации переменных ок-ружения Kettle см. листинг 1..
Листинг 1. Метод инициализации Kettle
/***
*Метод для инициализации Kettle Repository
*@return repository
*/
1. public Repository initKettle(){
2. Repository repK= null;
3. EnvUtil.environmentInit();
4. log.info("Setting up DatabaseMeta");
5. dbMeta =new DatabaseMeta();
6. dbMeta.setName(this.repositoryName);
7. dbMeta.setAccessType(DatabaseMeta.TYPE_ACCESS_JNDI);
8. dbMeta.setDBName("java:kettleDatasources/" + this.repositoryName);
9. try {
10. database = new Database(dbMeta);
11. database.connect();
12. log.info("DatabaseMeta set up done");
13. /* Load the plugins etc.*/
14. StepLoader steploader = StepLoader.getInstance();
15. if (!steploader.read()) {
16. log.info( "Error loading steps... halting Kitchen!");
17. System.exit(8);
18. }
19. jeloader = JobEntryLoader.getInstance();
20. if (!jeloader.read())
21. {
22. log.info("Error loading job entries & plugins... halting Kitchen!");
23. System.exit(8);
24. }
25. RepositoryMeta rpMeta = new RepositoryMeta(this.getDbMeta().getName(),"",
26. this.getDbMeta());
27. UserInfo userInfo = new UserInfo();
28. userInfo.setLogin(this.getUserKettle());
29. userInfo.setPassword(this.getPassKettle());
30. repK = new Repository( logKettle,rpMeta,userInfo);
31. repK.connect( dbMeta.getName());
32. }
33. catch (KettleDatabaseException ex) {
34. ex.printStackTrace();
35. }
36. catch (KettleException ex) {
37. ex.printStackTrace();
38. }
39. return repK;
40. }
На первом этапе инициализируется источник данных, строки 4-12, в котором нахо-дится хранилище Kettle, используя JNDI контекст. Далее следует заметить, что объект job, состоит из последовательности различных единичных действий JobEntry, в которых мо-гут участвовать различные объекты, например, трансформация данных - transformation, прыжки – hop, указывающие очередность действий, SQL запросы к источникам данных и др. Поэтому для работы с объектом job необходимо загрузить библиотеки plugins, которые позволяют выполнять действия над различными типами объектов стр. 13-24. После чего происходит соединение с хранилищем Kettle 25-32, и далее могут выполняться любые действия с объектами репозитория.
Увязка планировщика выполнения job была выполнена следующим образом.
Планировщик работает внутри сервера приложений JBoss, его настройки хранятся в отдельной базе данных, скрипт для создания которой поставляется с пакетом quartz.
Единица работы планировщика связывается с объектом job – kettlа в отношении многие ко многим. В качестве связующего звена используется персистентный (persistens) бизнес-объект, который содержит следующие атрибуты jndi имя репозитория kettle, имя объекта job - kettle, имя и группа планировщика. Работа с ним производится с использова-нием библиотеки hibernate. В результате, как видно на рис 3. каждый объект - job kettle может иметь несколько планов выполнения (ExecutionPlan), история выполнения отобра-жается в JobExecutionHistory.
Интерфейс системы представлен на рис.3
Рисунок 3. Клиентский интерфейс системы.
Таким образом, использование для выполнения трансформации библиотеки kettle.jar фирмы pentaho позволяет: оперативно и качественно переносить данные с гетерогенных источников информации, выполнять быстро и качественно их разработку аналитиком – пользователем, не затрачивать дополнительные средства на приобретение, реализовать на ее базе полноценную BI систему.
Список используемых источников
- Жмайлов Б.Б. Способы переноса баз данных между различными субд на примере транзита с Microsoft SQL Server Express 2005 на MySQL 5.0. "Вестник компьютерных и информационных технологий" №5, 2007г.
- http://www-306.ibm.com/software/data/ips/products/masterdata/
- http://www.pentaho.com/products/data_integration/
ОАО "Ростовэнерго"



 Узнай о чем ты на самом деле сейчас думаешь
Узнай о чем ты на самом деле сейчас думаешь 

